
Алгоритм Хаффмана – это эффективный метод сжатия данных, использующий принцип «частотности символов». Принцип этот состоит в том, что часто встречающиеся символы кодируются короткими битовыми последовательностями, а редко встречающиеся символы – длинными. Благодаря этому алгоритму, можно достичь высокой степени сжатия файла, что делает его широко применяемым в современной информационной технологии.
Основная идея алгоритма Хаффмана заключается в построении оптимального префиксного кода для каждого символа. Оптимальность достигается путем выстраивания кода таким образом, чтобы сумма весов всех кодовых слов была минимальной. Это возможно благодаря использованию двоичного дерева Хаффмана, которое строится на основе частоты встречаемости символов в исходном тексте.
Применение алгоритма Хаффмана позволяет не только сжимать данные, но и распаковывать их обратно без потери информации. Для этого при сжатии сохраняется таблица частот символов, благодаря чему возможно правильное распаковывание и восстановление исходной информации. Это делает алгоритм Хаффмана универсальным и эффективным инструментом для сжатия и передачи данных.
Видео:Код ХаффманаСкачать

Основные принципы алгоритма Хаффмана
Процесс алгоритма Хаффмана может быть разбит на следующие шаги:
- Подсчет частоты встречаемости каждого символа в исходном файле или сообщении.
- Создание бинарного дерева Хаффмана на основе частоты символов.
- Кодирование символов, используя пути от корня дерева к каждому символу.
- Создание сжатого файла, заменяя каждый символ исходного файла его соответствующим кодом.
Основная идея алгоритма Хаффмана заключается в том, что символы, которые встречаются чаще всего, получают более короткие коды, что позволяет снизить общий размер сжатого файла. Алгоритм Хаффмана позволяет достичь оптимального сжатия без потери данных. Он может использоваться для сжатия различных типов данных, включая текстовые документы, изображения и звуковые файлы.
Видео:Кодирование Хаффмана (пример)Скачать
Сжатие данных
Алгоритм Хаффмана достигает сжатия данных путем присвоения более короткого кода наиболее часто встречающимся символам или последовательностям символов в исходных данных. Это основывается на идее, что частота появления символа или последовательности символов в тексте является показателем его важности.
За счет используемых коротких кодов, алгоритм Хаффмана может значительно уменьшить размер файла или передаваемых данных. Это особенно полезно при передаче больших объемов информации через сеть или хранении больших файлов на диске.
Помимо сжатия данных, алгоритм Хаффмана также обеспечивает эффективное использование ресурсов. Он может быть реализован с помощью простых структур данных и требует небольшого количества памяти для хранения таблицы символов и дерева Хаффмана.
Однако следует иметь в виду, что сжатие данных алгоритмом Хаффмана является потерьным процессом, что означает, что часть информации может быть потеряна в результате сжатия. Это связано с тем, что алгоритм стремится убрать ненужную информацию и сосредоточиться на наиболее важной части.
4. Эффективное использование ресурсов
В отличие от других методов сжатия данных, алгоритм Хаффмана применяет два основных принципа, позволяющих достичь высокой эффективности:
1. Принцип переменной длины кодирования.
Алгоритм Хаффмана кодирует символы с использованием кодов переменной длины. Это означает, что каждый символ может иметь свой собственный код, который может быть более или менее длинным в зависимости от частоты его встречаемости в исходном тексте. Таким образом, часто встречающиеся символы будут закодированы более короткими кодами, а редко встречающиеся символы — более длинными. Это позволяет существенно снизить объем закодированных данных и обеспечить эффективное использование доступных ресурсов.
2. Принцип оптимальности.
Алгоритм Хаффмана строит оптимальное префиксное кодовое дерево, в котором более часто встречающиеся символы имеют более короткий код. Это достигается путем построения дерева снизу вверх, начиная с отдельных символов и последовательно объединяя их вложенные поддеревья. В результате получается кодовое дерево, в котором не существует двух символов, имеющих одинаковый префикс, что обеспечивает оптимальность кодирования и минимизацию объема закодированных данных.
Благодаря этим принципам, алгоритм Хаффмана обладает высоким уровнем сжатия данных и эффективным использованием ресурсов. Он нашел широкое применение в таких областях, как сжатие текстовых файлов, аудио и видео кодеки, а также в сетевых протоколах для передачи данных через ограниченные каналы связи.
Потерьность сжатия
В основе алгоритма Хаффмана лежит идея о том, что наиболее часто встречающиеся символы занимают меньше места, а редко встречающиеся символы занимают больше места в сжатом виде. Однако, при таком подходе возникает проблема выбора оптимального кодирования для символов, которые встречаются редко или только один раз.
Алгоритм Хаффмана решает эту проблему путем создания дерева, в котором каждый символ представлен уникальным кодом. Однако, при этом теряется информация о кодировании редких символов, так как сжатие основывается на частоте их встречаемости в исходных данных. В результате, при раскодировании сжатых данных, информация о некоторых символах может быть утрачена.
Тем не менее, потери, которые возникают при использовании алгоритма Хаффмана, обычно несущественны для текстовых данных. В большинстве случаев потери при сжатии данных с помощью алгоритма Хаффмана незаметны для обычного пользователя, и сжатые данные остаются вполне читаемыми и используемыми. Это позволяет эффективно использовать алгоритм Хаффмана при сжатии текстовых файлов и передаче данных по сетям.
Видео:Метод ХаффманаСкачать

Структура данных алгоритма Хаффмана
Строится дерево Хаффмана по следующему алгоритму:
- Для каждого символа из исходного текста подсчитывается его частота.
- Создается список, в котором каждый элемент — узел дерева, содержащий символ и его частоту.
- Сортируется список по возрастанию частоты символов.
- Пока в списке не останется только один элемент:
- Извлекается первые два узла с наименьшими частотами.
- Создается новый узел, который становится родительским для двух извлеченных узлов.
- Частота нового узла равна сумме частот двух извлеченных узлов.
- Новый узел добавляется в список.
- Сортируется список по возрастанию частоты символов.
- Полученный элемент списка является корнем дерева Хаффмана.
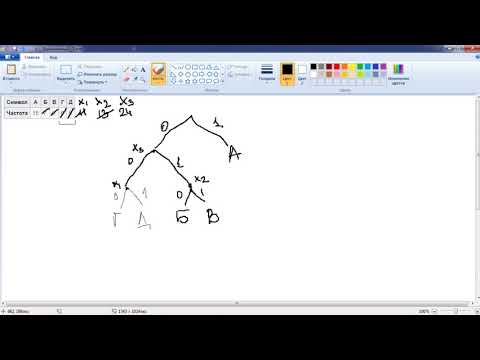
Каждый узел дерева Хаффмана имеет два потомка — левого и правого. Левый потомок соответствует символу с меньшей частотой, а правый потомок — символу с большей частотой. Листья дерева Хаффмана соответствуют исходным символам, а пути от корня до листа определяют код символа.
Код символа представляется в виде битовой последовательности, где каждому символу сопоставляется уникальная последовательность битов. Такой код называется префиксным кодом, то есть ни одна кодовая последовательность не является префиксом другой кодовой последовательности.
Структура данных алгоритма Хаффмана позволяет эффективно кодировать символы и осуществлять сжатие данных. Кодирование происходит следующим образом: каждый символ из исходного текста заменяется соответствующей последовательностью битов из кода символа.
7. Дерево Хаффмана
Процесс построения дерева Хаффмана начинается с создания листьев для каждого символа исходного текста, а затем объединения этих листьев в узлы согласно их частоте встречаемости. На каждом этапе выбираются два узла с наименьшей частотой и создается новый узел, суммировавший частоты этих узлов. Этот процесс повторяется до тех пор, пока все узлы не будут объединены в один корень дерева.
Дерево Хаффмана имеет следующие свойства:
| Свойство | Описание |
|---|---|
| Префиксный код | Каждый символ в дереве Хаффмана имеет уникальный префиксный код, которые не являются префиксом для других символов. |
| Эффективное кодирование | Коды символов в дереве Хаффмана имеют различную длину, причем наиболее часто встречающиеся символы имеют самые короткие коды. Это обеспечивает эффективность сжатия данных. |
| Уникальность кодов | Коды символов в дереве Хаффмана являются уникальными, что позволяет безошибочно идентифицировать каждый символ при декодировании сжатых данных. |
Использование дерева Хаффмана позволяет эффективно сжимать информацию, сохраняя при этом все исходные данные. Этот алгоритм широко применяется в архиваторах данных для уменьшения объема хранимой или передаваемой информации.
Кодирование символов в алгоритме Хаффмана
В алгоритме Хаффмана каждому символу присваивается его уникальный код. Этот код строится на основе частотности встречаемости символа в исходном тексте. Символы, которые встречаются чаще всего, получают коды, которые состоят из меньшего числа бит. Таким образом, символы, которые встречаются реже, получают более длинные коды.
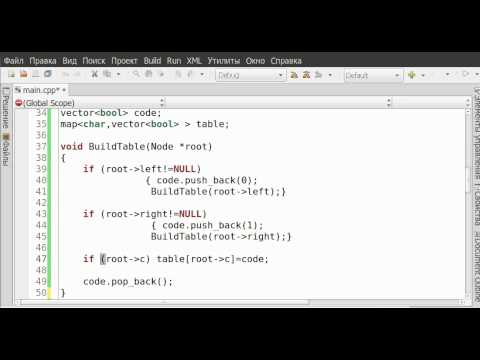
Кодирование символов осуществляется при помощи двоичного дерева Хаффмана. В этом дереве каждый символ представлен листом, а ветви дерева соответствуют битам кода. Проходя по дереву от корня к конкретному символу, можно определить его код.
Кодирование символов в алгоритме Хаффмана обеспечивает эффективность сжатия данных. Коды символов, которые встречаются чаще всего, являются более короткими, что позволяет сэкономить место при хранении и передаче данных. Однако, кодирование символов также влечет потерю информации, так как оригинальные символы заменяются более компактными кодами. При декодировании эти коды восстанавливаются в оригинальные символы.
Таким образом, кодирование символов является важной функциональностью алгоритма Хаффмана. Она позволяет достичь сжатия данных и эффективно использовать ресурсы при их хранении и передаче.
Видео:Код ХаффманаСкачать
Функциональность алгоритма Хаффмана
Алгоритм Хаффмана предоставляет функциональность сжатия данных путем создания оптимального префиксного кода для каждого символа в исходном наборе данных. Этот код состоит из последовательности битов, которые затем могут быть использованы для эффективного представления исходных данных.
Функциональность алгоритма Хаффмана основана на следующих принципах:
- Символы с более высокой вероятностью появления в исходных данных получают короткий код, тогда как символы с более низкой вероятностью получают более длинный код.
- Алгоритм Хаффмана строит оптимальное кодовое дерево, используя частоты появления символов исходных данных, чтобы максимально снизить общую длину кода.
- Кодовое дерево Хаффмана представляет собой бинарное дерево, в котором каждый внутренний узел имеет два дочерних узла, представляющих двоичные комбинации символов.
- Кодирующая таблица, созданная на основе кодового дерева, используется для преобразования каждого символа исходных данных в соответствующий код Хаффмана.
Функциональность алгоритма Хаффмана позволяет достичь эффективного сжатия данных без потери информации. Сжатые данные могут быть восстановлены обратно в исходный формат с использованием той же кодирующей таблицы и кодового дерева Хаффмана.
Видео:Код ХаффманаСкачать

Архивация данных
Архивация данных происходит путем замены исходной последовательности символов более короткими кодами, которые формируются на основе частоты их появления в исходных данных. Часто встречающиеся символы получают более короткие коды, что позволяет существенно уменьшить общий размер данных.
Алгоритм Хаффмана генерирует оптимальные коды для каждого символа, основываясь на их частоте появления в исходных данных. Это означает, что более часто встречающиеся символы будут иметь более короткие коды, а редко встречающиеся символы — более длинные коды.
Преимущество архивации данных с использованием алгоритма Хаффмана в том, что он позволяет сжимать данные таким образом, чтобы они могли быть эффективно восстановлены без потерь исходной информации. Например, при архивации текстового файла символы текста будут заменены их бинарным представлением, но при деархивации данные будут восстановлены в исходном виде без потерь информации.
Алгоритм Хаффмана широко применяется в различных областях, где необходимо сжатие данных, таких как передача файлов по сети, архивирование и хранение файлов, компрессия видео и аудио. Благодаря своей эффективности и простоте реализации, алгоритм Хаффмана продолжает быть одним из самых популярных алгоритмов архивации данных.
🌟 Видео
Java. Алгоритм Хаффмана для компрессии данных.Скачать

Код ХэммингаСкачать

Алгоритмы теория и практика Методы - 70 урок. Практика на Python: Коды ХаффманаСкачать

алгоритм ХаффманаСкачать

Алгоритм Хаффмана C++Скачать
Часть 2. Сам алгоритм ХаффманаСкачать

Юникод, префиксные коды, код Хаффмана | СкринкастыСкачать

Часть 1. Пишем алгоритм Хаффмана на C++Скачать
ДМ 1 курс - 7 лекция - коды, префиксные коды, алгоритм Хаффмана, неравенство Крафта-МакМилланаСкачать

Программирование - Кодирование по алгоритму Хаффмана на PythonСкачать
Построение таблиц истинностиСкачать

Введение в программирование №12. Алгоритм ХаффманаСкачать

Алгоритм Хаффмана и Шеннона. Условия Фано | ЕГЭ 2022 | 99 Баллов | ИнформатикаСкачать
Метод Хаффмана в ExcelСкачать
Построение схем по логическим выражениямСкачать
