
Каждый символ, который мы используем на компьютере или мобильном устройстве, имеет свой уникальный код. Но где именно хранится этот код? Ответ на этот вопрос связан с передачей информации, обработкой данных и многочисленными технологическими деталями. Приготовьтесь к глубокому погружению в мир кодирования символов!
Одним из самых известных и широко используемых способов хранения кодов символов является таблица символов Unicode. Unicode – это стандарт, который обеспечивает уникальные коды для почти всех символов, используемых в различных языках и письменностях мира. В таблице символов Unicode каждому символу соответствует свой уникальный номер.
Внутри компьютера или другого устройства, коды символов хранятся в виде двоичных чисел. Каждый символ представлен в памяти устройства с помощью определенного количества битов. Например, для хранения кодов символов Unicode используется 16-битное представление, что позволяет закодировать до 65536 различных символов. Однако, с развитием технологий расширение Unicode до 32-битного представления стало возможным, что увеличило количество символов, которые можно кодировать.
Видео:Что такое таблица ASCII и как получить код символа на C#Скачать
Места хранения кода символа
Кодировочные таблицы являются одним из основных мест хранения кодов символов. Это специальные таблицы, которые сопоставляют числовой код символа с его графическим представлением. Наиболее часто используемыми кодировочными таблицами являются ASCII, Unicode, UTF-8 и UTF-16. Каждая таблица имеет свою уникальную нумерацию символов и определенные правила для сопоставления кодов и графического представления.
Юникод – это международный стандарт, который объединяет символы из различных письменностей и культур и присваивает им уникальные коды. Юникод позволяет представлять символы из всех возможных письменностей, включая латиницу, кириллицу, китайские иероглифы и множество других. Коды символов Юникода могут быть хранены в различных форматах, таких как UTF-8 и UTF-16.
Способы хранения кода символа могут варьироваться в зависимости от контекста использования. Одним из основных мест хранения кодов символов является память компьютера. Коды символов могут быть представлены в виде байтов или битов и сохранены в оперативной памяти для обработки и отображения. Однако, коды символов также могут быть хранены в файловой системе компьютера, например, в текстовых файлах или базах данных, чтобы обеспечить их сохранность и доступность при перезагрузке или обмене данными.
Кодировочные таблицы
В настоящее время существует множество различных кодировочных таблиц, таких как ASCII, UTF-8, UTF-16 и др. Каждая из этих таблиц предоставляет уникальный способ представления символов и определяет набор числовых значений, которые соответствуют определенным символам.
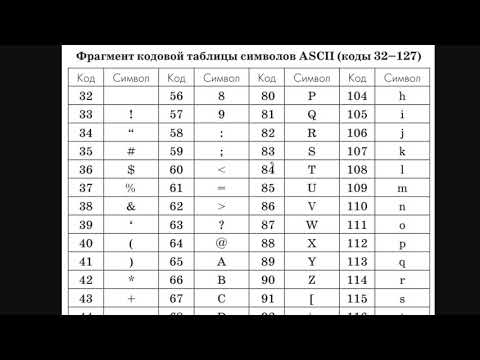
ASCII (American Standard Code for Information Interchange) — это одна из самых популярных и широко используемых кодировочных таблиц. Она включает в себя 128 базовых символов, таких как латинские буквы, цифры, знаки препинания и управляющие символы. ASCII была разработана в 1960-х годах и до сих пор активно используется во множестве приложений и систем.
Однако ASCII имеет ограниченную поддержку для символов, используемых в других языках, и не может правильно отобразить их. Это привело к разработке более мощных и универсальных кодировочных таблиц, таких как UTF-8 и UTF-16.
UTF-8 (Unicode Transformation Format, 8-bit) — это кодировочная таблица, которая может представить практически все символы из всех возможных письменных систем. Она использует разные длины кодов для разных символов, включая ASCII, что позволяет совместимость с существующими системами и обеспечивает эффективное использование памяти.
UTF-16 (Unicode Transformation Format, 16-bit) — это еще более расширенная кодировочная таблица, которая использует 16-битные коды для представления символов. Она позволяет представлять все символы из всех возможных письменных систем, включая символы старых и редко используемых языков.
Кодировочные таблицы являются неотъемлемой частью современных компьютерных систем и позволяют эффективно хранить и передавать символы. Правильное использование кодировочных таблиц гарантирует корректное отображение символов и обеспечивает совместимость между различными системами и языками.
Юникод
Чтобы представить символы в Юникоде, используется 16-битный шестнадцатеричный код, называемый кодовой точкой. Каждому символу назначается уникальный кодовый номер, который может быть представлен в виде числа или шестнадцатеричного значения. Юникод определяет более 1,1 миллиона кодовых точек для представления символов.
Юникод предоставляет несколько различных способов представления символов, включая UTF-8, UTF-16 и UTF-32. UTF-8 использует переменную длину кодирования, что означает, что символы могут занимать разное количество байт в зависимости от их кодовой точки. UTF-16 использует 16-битные блоки для представления символов, а UTF-32 использует 32-битные блоки для представления символов.
Юникод широко используется в различных областях, включая программирование, веб-разработку, мобильные приложения, научные исследования и техническую документацию. Он обеспечивает однозначное и межоперационное представление символов, что делает его незаменимым инструментом для глобального обмена информацией и поддержки различных языков и письменных систем.
| Кодовая точка | Шестнадцатеричное значение | Символ |
|---|---|---|
| U+0041 | 41 | A |
| U+03B1 | 3B1 | α |
| U+2603 | 2603 | ☃ |
В таблице приведены примеры кодовых точек Юникода, их шестнадцатеричные значения и соответствующие символы. Каждый символ имеет уникальный кодовый номер, что позволяет программам и системам однозначно идентифицировать и обрабатывать символы из различных письменных систем.
Видео:КАК РАБОТАЮТ КОДИРОВКИ | ОСНОВЫ ПРОГРАММИРОВАНИЯСкачать

Способы хранения кода символа
Код символа может быть хранен различными способами, в зависимости от контекста использования и характеристик системы.
Один из способов хранения кода символа — это использование таблицы символов. В таблице символов каждому символу сопоставляется определенный код. Это позволяет компьютеру правильно интерпретировать и отображать символы на экране. Коды символов в таблице могут быть представлены в различных форматах, таких как ASCII, Unicode и другие.
Другой способ хранения кода символа — это использование кодировочных таблиц. Кодировочные таблицы представляют собой специальные наборы символов, которые устанавливают соответствие между символами и их кодами. Кодировочные таблицы могут содержать символы разных языков и специальные символы, такие как знаки препинания и математические символы.
Одно из современных средств хранения кода символа — это использование Юникода. Юникод представляет собой универсальную систему кодирования, которая позволяет представлять символы из всех конечных плоскостей Юникода. Это позволяет компьютерам и различным программам правильно обрабатывать и отображать символы на разных языках, включая символы редких и древних письменностей.
Способ хранения кода символа также зависит от места хранения. В памяти компьютера символы могут быть представлены в виде чисел или битовых последовательностей. В файловой системе символы могут быть хранены в виде текстовых файлов, где каждый символ представлен своим кодом.
В итоге, способы хранения кода символа многообразны и зависят от различных факторов. Выбор конкретного способа зависит от контекста использования и требований приложения или системы.
В памяти компьютера
В памяти компьютера код символа может быть представлен различными форматами данных. Например, они могут быть представлены в виде последовательности битов или чисел.
Для хранения кода символа в памяти компьютера также могут использоваться специальные структуры данных. Например, строка символов может быть представлена в виде массива символов, где каждый символ имеет свой уникальный код.
Кроме того, код символа может быть организован в виде дерева или других сложных структур данных. Это может быть полезно для оптимизации доступа к символам и ускорения выполнения операций над ними.
Выбор способа хранения кода символа в памяти компьютера зависит от множества факторов, таких как требования к скорости доступа к символам, объем памяти, доступная для хранения символов, и другие.
| Формат хранения | Описание |
|---|---|
| ASCII | Однобайтовый формат хранения символов, используемый в старых системах. |
| UTF-8 | Многоязычный формат хранения символов, поддерживающий символы из различных языков, включая символы Юникода. |
| UTF-16 | Двухбайтовый формат хранения символов, используемый для представления символов Юникода. |
| UTF-32 | Четырехбайтовый формат хранения символов, используемый для представления символов Юникода. |
| … | И другие форматы хранения символов, применяемые в различных системах и языках программирования. |
Таким образом, хранение кода символа в памяти компьютера является важным аспектом при работе с символами и строками в программировании.
В файловой системе
Код символа также может быть хранен в файловой системе компьютера. Файловая система представляет собой специальную организацию и управление файлами, которые хранятся на жестком диске или других носителях информации. Каждый файл имеет свое уникальное имя и расширение, по которым его можно идентифицировать и отличить от других файлов.
Когда символы или текст записываются в файл, они преобразуются в соответствующие коды символов и сохраняются в бинарном виде. Это означает, что каждый символ представлен определенным числом, которое может быть сохранено в виде последовательности битов. Таким образом, код символа хранится в файле в виде последовательности чисел, которые можно интерпретировать как символы при чтении файла.
Однако, при работе с файлами важно помнить, что кодировка символов может меняться в зависимости от используемой файловой системы. Некоторые файловые системы могут использовать определенные кодировки, которые могут отличаться от стандартных кодировок, таких как ASCII или UTF-8. Поэтому при чтении или записи файлов важно учитывать используемую кодировку, чтобы правильно интерпретировать сохраненные символы.
В общем, хранение кода символа в файловой системе позволяет сохранять и передавать текстовую информацию между различными компьютерами и программами. Это делает файловую систему одним из наиболее универсальных способов хранения и обмена текстовой информацией, который используется повсеместно в современных компьютерных системах.
🎥 Видео
Что такое ascii символы. ascii что это такое? Таблица ascii c++. C ++ Для начинающих. Урок #62Скачать

Двоичная система счисления — самое простое объяснениеСкачать

Просто о битах, байтах и о том, как хранится информация #2Скачать

Что такое unicode, ascii, utf-8, utf-16, utf-32 ?Скачать

Информатика. Архитектура ПК: Представление целых чисел в памяти ПК. Центр онлайн-обучения «Фоксфорд»Скачать

Метод ХаффманаСкачать

ИНФОРМАТИКА 10 класс: Кодирование текстовой информацииСкачать

Алфавитный подход к определению количества информацииСкачать

КАК РАБОТАЕТ ZIP АРХИВ? | РАЗБОРСкачать

Уверен, что понимаешь как #хэшировать пароли правильно?Скачать

Уроки C++ / #10 урок - Строки и символыСкачать

Что такое ХЭШ функция? | Хеширование | Хранение паролейСкачать

Метод Шеннона-ФаноСкачать

Таблица кодировки cp1251 и utf8 в Java. Задача Tinkoff. Часть 1/2.Скачать

Кодирование информации | Информатика 5 класс #10 | ИнфоурокСкачать

Решение задачи по теме "Информационный объём сообщения"Скачать

Архитектура ПК: Представление вещественных чисел в памяти ПК. Центр онлайн-обучения «Фоксфорд»Скачать

Python и переменные окружения | Где и как хранить секреты в коде | .env, .gitignoreСкачать
