
ASCII (American Standard Code for Information Interchange) была одной из самых ранних кодировок, которая позволяла представить все основные символы английского алфавита, числа и пунктуацию. Однако, она не содержала символов кириллицы, что создавало проблемы для тех, кто использовал русский язык.
ISO-8859-1 (также известный как Latin-1) был первым шагом в направлении поддержки символов не только английского алфавита, но и ряда других языков, включая кириллицу. Однако, многое было оставлено неподдержанным, и кодировка не была универсальной.
Windows-1251 стал одной из самых популярных кодировок кириллицы, так как была использована в Microsoft Windows. Она была расширением ISO-8859-1 и позволяла пользователю использовать символы кириллицы, не теряя совместимость с английским текстом.
UTF-8 (Unicode Transformation Format, 8-bit) стал одним из самых универсальных способов представления символов всех языков мира. Это был масштабируемый вариант Unicode, который мог представить любой символ в определенном количестве байтов. UTF-8 стал основным стандартом во многих приложениях и позволяет создавать многоязыковые документы.
Видео:КАК РАБОТАЮТ КОДИРОВКИ | ОСНОВЫ ПРОГРАММИРОВАНИЯСкачать

ASCII: первая кодировка
ASCII использовался исключительно для английского языка и не содержал символов кириллицы. Однако, с появлением компьютеризации и распространением компьютеров в странах с кириллическим алфавитом, возникла необходимость в разработке новых кодировок, которые позволяли бы работать с кириллическими символами.
Ограничения ASCII заключались в том, что он мог представлять только символы из своего набора, а иные символы, включая кириллические, были необозримыми. Обработка кириллицы была невозможна в системах, работающих на ASCII.
Для решения этой проблемы были разработаны расширенные кодировки, в которых добавлены символы кириллицы, одной из которых стала кодировка KOI8. Об истории и особенностях кодировки KOI8 расскажем в следующем пункте статьи.
Описание ASCII
Алфавит ASCII включает в себя буквы латинского алфавита (заглавные и строчные), цифры, знаки препинания и специальные символы, такие как пробел и перевод строки. Каждый символ представлен уникальным числовым значением, которое называется кодом символа.
Например, символ «A» представлен кодом 65, а символ «a» — кодом 97. Таким образом, каждому символу приписывается свой уникальный код, который позволяет компьютеру правильно интерпретировать и отображать символ на экране.
Сочетание кодов символов в строке образует текст, который может быть отображен на экране или сохранен в файле. Все символы ASCII имеют одинаковую ширину, что делает их простыми для отображения в текстовых редакторах и консольных окнах.
Ограничения ASCII
Ограничения ASCII включают невозможность представления символов не из латинского алфавита, таких как кириллица, и отсутствие поддержки различных алфавитов и письменностей. Чтобы справиться с этим, было необходимо разработать новые кодировки, которые могли бы поддерживать широкий спектр символов, включая кириллицу и другие языки.
Ограничения ASCII омрачали использование кириллицы на компьютерах и создавали проблемы при обмене текстовой информацией между разными системами. Для решения этих проблем были созданы расширенные ASCII-кодировки, такие как ISO 8859, которые добавляют больше символов в диапазон от 128 до 255.
Однако, даже расширенные ASCII-кодировки оставались недостаточно универсальными для полной поддержки всех символов кириллицы. Было необходимо разработать новую кодировку, специально предназначенную для кириллицы — KOI8.
Видео:Понимание Юникода и UTF-8Скачать

Проблемы с кириллицей в ASCII
Кодировка ASCII была разработана в начале 1960-х годов и изначально предназначалась для использования только с английским алфавитом. Однако, когда стало необходимым представлять другие языки, такие как кириллица, в рамках кодировки ASCII возникли проблемы.
Основная проблема заключалась в том, что оригинальная кодировка ASCII содержала только 7 бит, что позволяло кодировать только 128 символов, включая буквы латинского алфавита, цифры и некоторые специальные символы. Для того чтобы представить символы кириллицы, необходимо было использовать дополнительные биты, которые не были предусмотрены в оригинальной спецификации ASCII.
В результате отсутствия поддержки кириллических символов в ASCII, множество различных расширенных ASCII-кодировок были созданы для представления кириллицы. Эти кодировки присваивали специфические значения кириллическим символам, что позволяло приложениям поддерживать работу с кириллицей в ограниченных рамках ASCII. Однако, использование различных кодировок усложняло обмен данными между различными системами, так как каждая система могла использовать свою собственную кодировку.
Таким образом, отсутствие кириллических символов в оригинальной кодировке ASCII и нестандартизированные расширенные ASCII-кодировки создавали значительные проблемы для использования кириллицы в компьютерных системах. Данная ситуация стала основной мотивацией для появления новой универсальной кодировки, которая смогла бы представлять символы различных языков, включая кириллицу.
Отсутствие кириллических символов в ASCII
Из-за отсутствия кириллических символов в ASCII, при использовании этой кодировки для представления текста на русском языке возникали определенные проблемы. Русские буквы нельзя было корректно отобразить или передавать при использовании только ASCII символов.
Это значительно ограничивало возможности работы с русским языком в области компьютерных технологий. Кириллические символы не могли быть использованы в именах файлов, внутри программных кодов, а также в URL-адресах.
В результате, разработчики столкнулись с проблемой, как включить кириллические символы в кодировку и обеспечить корректное представление русского языка на компьютерах. Эта проблема была решена созданием расширенных ASCII-кодировок и, в конечном итоге, разработкой новых стандартов кодировки, поддерживающих кириллицу.
Кириллица в расширенных ASCII-кодировках
ASCII, хоть и было первым стандартом для кодирования текста на компьютерах, имел свои ограничения и не поддерживал кириллицу напрямую. Однако, с развитием технологий, появились расширенные ASCII-кодировки, которые решали эту проблему.
В этих кодировках были добавлены специальные символы, отображающие кириллицу. Наиболее известными и широко используемыми из них были кодировки Windows-1251 и ISO-8859-5. Эти кодировки расширяли оригинальный ASCII-набор и добавляли в него кириллические символы.
В кодировке Windows-1251 каждому кириллическому символу соответствовал свой байт кода. Это позволяло передавать и отображать кириллицу на компьютерах, поддерживающих данную кодировку. В то же время, ISO-8859-5 предлагала аналогичные возможности для кириллицы.
Однако, использование этих кодировок также имело свои недостатки. Как и ASCII, они обладали ограничениями, не позволяли отобразить все кириллические символы. Например, в кодировке Windows-1251 отсутствовала возможность отобразить букву Ё. Также, проблема возникала при попытке передачи текста, закодированного в одной из этих кодировок, на компьютеры, которые не поддерживали данную кодировку.
Таким образом, хоть расширенные ASCII-кодировки улучшили ситуацию с отображением кириллицы, они все же были не идеальными. В дальнейшем, разработчики стремились создать более универсальные и расширяемые стандарты, что привело к появлению кодировок UTF-8 и UTF-16, обеспечивающих полную поддержку всех символов кириллицы и других мировых языков.
Видео:Как сделать кодировку UTF-8Скачать
Кодировка KOI8: переход к кириллице
История создания кодировки KOI8 началась в 1973 году в Институте Кибернетики Советской Академии Наук (ИК САН). Целью данного проекта было создание стандарта, который бы позволил передавать и отображать кириллический текст на компьютерах разных производителей.
Особенностью кодировки KOI8 является использование 8-битных кодов для представления символов. Это позволяет кодировке использовать в обозначении кириллических букв специальные символы, которые отличаются от символов английского алфавита.
Кодировка KOI8 содержит 256 символов, включая все буквы русского алфавита (крупные и строчные), а также различные знаки препинания и символы математических операций. При этом некоторые символы в кодировке KOI8 обладают особыми свойствами. Например, кириллические символы псевдографики, позволяющие создавать различные рисунки и диаграммы.
Кодировка KOI8 стала популярной в Советском Союзе и других странах Восточной Европы. Она использовалась в операционных системах, текстовых редакторах, электронной почте и других приложениях. Однако, с развитием компьютерной техники и появлением более современных кодировок, кодировка KOI8 постепенно уступила свои позиции.
Сегодня кодировка KOI8 все еще используется в некоторых старых системах и оставляет свой след в истории развития компьютерных технологий. Она является примером того, как создание эффективных и универсальных способов представления и обмена информацией помогает унифицировать и улучшить работу с текстом на разных языках.
Использование кодировки KOI8 требует определенного программного обеспечения и настроек, чтобы корректно отображать и обрабатывать текст на компьютере. Поэтому, при работе с кириллическим текстом, рекомендуется использовать более современные и универсальные кодировки, такие как UTF-8, которые поддерживаются практически всеми современными операционными системами и программами.
История создания кодировки KOI8
Кодировка KOI8 (Код Обмена Информацией, 8-бит) была разработана в Советском Союзе в 1970-х годах. Создание KOI8 было сопряжено с необходимостью осуществить переход от кодировки ASCII к кодировке, которая поддерживала бы кириллические символы.
Создание KOI8 велось под руководством Анатолия Штерна, который в то время работал в Институте проблем передачи информации Академии наук СССР. Штерн и его коллеги разработали кодировку, которая заменила латинские символы, редко используемые специальные символы и символы, которые отсутствовали в классическом ASCII, на кириллические символы.
Кодировка KOI8 содержала 256 символов, и она использовала все 8 битов в байте. Поэтому KOI8 была полностью совместима с ASCII. Это означало, что при использовании KOI8 можно было передавать тексты, написанные на латинице, и обрабатывать их, не теряя информации.
После создания кодировки KOI8 она была стандартизирована и одобрена в 1984 году. С тех пор KOI8 стала широко использоваться в Советском Союзе и других странах, где преобладала кириллица. Кодировка KOI8 была также востребована в электронной почте и в сетях передачи данных.
Несмотря на свою популярность, кодировка KOI8 имела свои недостатки. Одним из основных недостатков было отсутствие поддержки других языков, таких как украинский и белорусский. Кроме того, KOI8 не была единой для всех советских стран, и существовало несколько вариантов этой кодировки, которые различались по расположению символов.
Однако кодировка KOI8 оказала значительное влияние на дальнейшую разработку кодировок, включая кодировку Windows-1251, которая стала заменой KOI8 в операционной системе Windows.
Особенности кодировки KOI8
Особенностью кодировки KOI8 является то, что она может представлять кириллические символы в их оригинальном порядке, без необходимости отображения их в обратном порядке, как это было в ASCII. Это позволяет более удобно работать с кириллицей и делает ее более читаемой для пользователей.
Еще одной особенностью кодировки KOI8 является ее совместимость с ASCII. Это означает, что текст, закодированный в KOI8, может быть корректно интерпретирован программами, которые ожидают ASCII-текст. Это существенно упрощает процесс обмена информацией между различными системами и программами.
Кроме того, кодировка KOI8 поддерживает не только кириллические символы, но и латинские символы, что позволяет ее использовать в многоязычных текстах. Также существуют различные варианты кодировки KOI8, которые предназначены для разных языков и регионов, такие как KOI8-R для русского языка и KOI8-U для украинского языка.
Важно отметить, что кодировка KOI8 является устаревшей и менее распространенной в настоящее время. Она была заменена более новыми кодировками, такими как Windows-1251 и UTF-8, которые поддерживают большее количество символов и более широко используются в современных компьютерных системах.
Тем не менее, кодировка KOI8 играла важную роль в истории кодировок кириллицы и оставила значительный след в различных областях, включая программирование, интернет и электронную почту.
📺 Видео
Как исправить текст сайта поменять кодировку utf-8 сделать сайт Set Character Encoding 😎 Урок 7.1Скачать
Как компьютер кодирует символы (кодировки, encodings)Скачать

ПРОБЛЕМЫ С КОДИРОВКОЙ. Utf8 в Windows? Кодировка utf8 sublime textСкачать

Решение проблемы с кодировкой КИРИЛЛИЦЫ в VSCODEСкачать

Что такое unicode, ascii, utf-8, utf-16, utf-32 ?Скачать

Как изменить кодировку в WordСкачать

Что такое ascii символы. ascii что это такое? Таблица ascii c++. C ++ Для начинающих. Урок #62Скачать

Кодировки ANSI, UTF-8 и Unicode - Чем отличаются?Скачать

Решение проблемы с кодировкой символов на сайте (UTF-8). Отображает иероглифы или знаки вопросаСкачать
КАК УБРАТЬ ИЕРОГЛИФЫ (КРАКОЗЯБРЫ) EXCEL ПРОБЛЕМЫ С КОДИРОВКОЙ 1251 UTF 8Скачать

C++ не читает кириллицу с файла! (Решение проблемы)Скачать
Двоичная система счисления — самое простое объяснениеСкачать

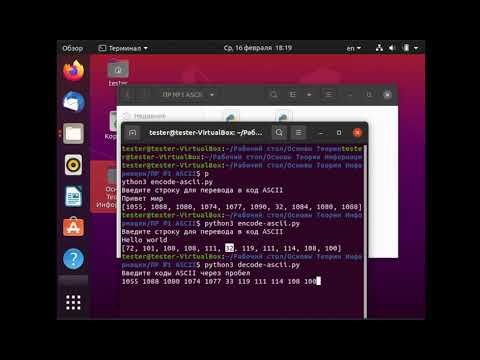
Кодирование и декодирование в ASCIIСкачать
Что такое Кодировка? (Character Encoding, Кодировка Символов, UTF-8, Windows-1251) #ShortsСкачать

Программирование на Python - 09 - Строки и Кодировки. ASCII UTF-8Скачать
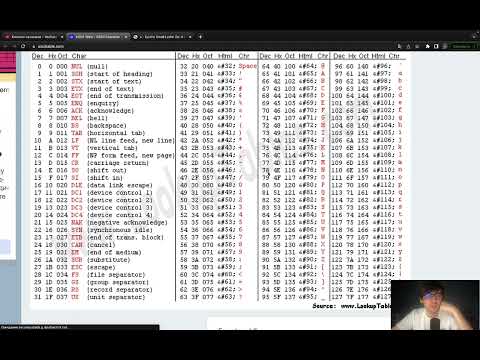
Кодирование текстовой информацииСкачать
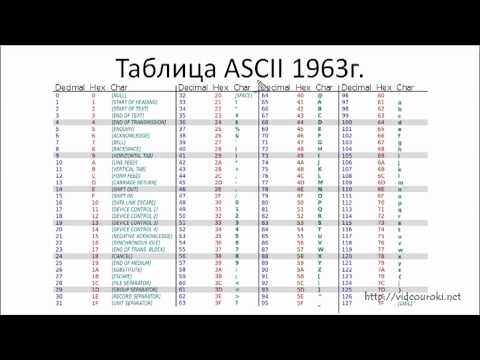
ИНФОРМАТИКА 10 класс: Кодирование текстовой информацииСкачать
